Videostroboskopie ist eine der weit verbreitesten Diagnosemethoden in der Phoniatrie und Pädaudiologie. Warum benötigen wir aber eine Videoendosokopie? Die Stimmlippen bewegen sich mit mehreren hundert Hertz, viel zu schnell für konventionelle Kameras. Das Bild ist verschwommen und das ärztliche Personal kann schwierig Diagnosen stellen. Das folgende Video zeigt sehr schön den Unterschied zwischen normaler Videoendoskopie (kein Stroboskopeffekt, einfach nur eine konstante Lichtquelle) und der Videostroboskopie.
Das ganze basiert auf der Tatsache, dass wir das Audiosignal des Patienten/der Patientin verwenden, um die Fundamentalfrequenz F0 zu bestimmen. Dadurch können wir das Stroboskopie-Licht mit der Stimmlippenschwingung synchronisieren und die eigentlich zu langsame Kamera (die Aufnahmebildrate ist weit unter der Schwingfrequenz der Stimmlippen) zu guten Bildern motivieren, da nur Licht an den richtigen Zeitpunkten verfügbar ist. Folgende Abbildung stellt dies exemplarisch dar:
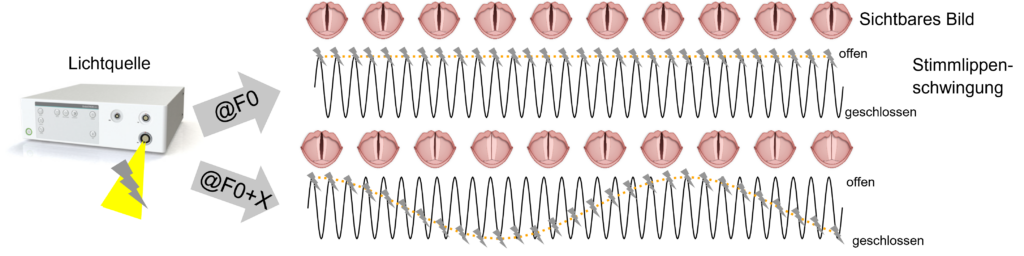
Das jetzige, audio-basierte System, hat allerdings einige Probleme:
- Wir benutzen Video-basierte und Audio-basierte Hardware, die nicht nur mehr Kosten verursacht, sondern auch synchronisiert werden muss.
- Das Audiosignal ist von Rauschen betroffen, je nachdem, wo das Mikrofon positioniert und eingestellt ist. Zudem weiß das Mikrofon nicht, wer der Patient und wer die Ärztin ist, so dass Instruktionen und Motivationen (“das machen Sie gut”, “jetzt lange iiiiiii machen”), ebenso aufgenommen werden und das Ergebnis verfälschen
- Patient*innen, die eine Stimmlippenschwingung haben, aber keinen Ton generieren (“aphon”), können nicht mit dem System adäquat versorgt werden.
Bilder statt Audio
Wir haben deswegen uns gefragt, ob wir nicht das Bildmaterial selbst nehmen können, um die Fundamentalfrequenz F0, also die wichtige Information, wann genau geblitzt werden muss, zu bestimmen. Wir hatten einige vorherige Arbeiten [zum Beispiel Kist et al., Scientific Reports 2021, und Kist und Döllinger, IEEE Access 2020] zusammen mit etablierter Literatur, die uns vermuten ließen, dass mit Künstlicher Intelligenz (KI) und dem Bildmaterial das Potential durchaus besteht.
Wir wussten, dass die Schwingungsfrequenz der Stimmlippen mit der Fundamentalfrequenz des Audiosignals übereinstimmt, da diese auch das Trägersignal für letzteres darstellen. Daher haben wir uns gefragt, ob wir nicht eine KI entwickeln können, die schnell und genau den relativen Öffnungsgrad der Stimmlippen vorhersagen kann:

Wir konnten zeigen, dass dies durchaus funktioniert, wenn wir tiefe neuronale Netze als KI-Methode verwenden:

Man sieht, es ist nahe an der Grundwahrheit dran, funktioniert aber nicht perfekt. Das gute daran ist: das muss es auch nicht. Es muss nur gut genug sein, so dass wir das Schwingverhalten gut abschätzen können.
Das Grundproblem ist, dass wir idealerweise bei mindestens der doppelten Frequenz abtasten müssen (das heißt 400 Bilder pro Sekunde, so dass wir ein Signal von 200 Hz bestimmen können). Das ist das sogenannte Shannon-Nyquist-Kriterium. Die Kameras, die aber in solchen Systemen verbaut sind, sind meistens viel langsamer, zwischen 80 und 250 Bilder pro Sekunde. Daher mussten wir uns noch einen Trick ausdenken:
Das Verfahren der komprimierten Erfassung (englisch: compressed sensing) erlaubt es, arbiträre Kurven durch zufällig aufgenommene Datenpunkte durch eine Optimierung zu rekonstruieren. Folgende Abbildung von Wikipedia veranschaulicht das sehr schön. Die schwarzen Punkte ist die Information, die uns zur Verfügung steht, das graue Signal die Grundwahrheit und in orange das vorhergesagte Signal.

In unserem Fall wäre dies das Schwingverhalten der Stimmlippen. Wenn wir mit zufälligen Blitzlichtern an unterschiedlichen Zeitpunkten abtasten und Bilder generieren, können wir mit Hilfe unserer KI den relativen Öffnungsgrad bestimmen. Die gepaarten Datenpunkte Zeitpunkt/relativer Öffnungsgrad ist dann die Grundlage für den compressed sensing Algorithmus.
Wenn wir beides kombinieren, können wir auf neuen Patient*innenaufnahmen zeigen, dass wir fast perfekt die Fundamentalfrequenz rekonstruieren können:
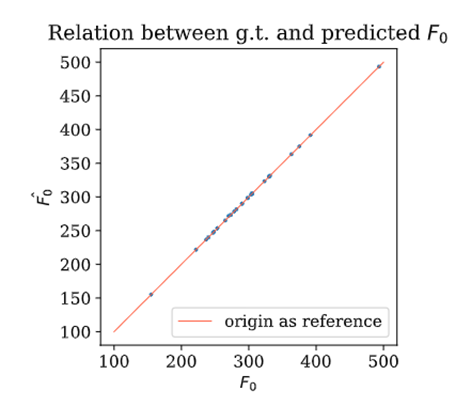
Wie würde jetzt der gesamte Ablauf des Systems sein, wenn es in der Klinik eingesetzt wird? Zuerst werden für ca. 250 ms zufällig Bilder aufgenommen, so dass wir die F0 erstmalig berechnen können. Anschließend verwenden wir diese F0 um die Stroboskopie-Einheit zu steuern. In einer Übersicht schaut das so aus:

Folgendes Video zeigt das Prinzip des “Samplings” (Daten aufnehmen für die Rekonstruktion) und des “Strobes” (angewandte F0, idealerweise Glottisstillstand) an verschiedenen Proband*innen:
Mehr Informationen finden Sie in unserer Originalarbeit:
Wölfl, A. M., Schützenberger, A., Breininger, K., & Kist, A. M. (2023). Towards image-based laryngeal videostroboscopy using deep learning-enabled compressed sensing. Biomedical Signal Processing and Control, 86, 105335.